
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- machinevision
- 산업대학원
- 영어기초
- Ai
- 특수대학원
- 직장인
- 영어공부
- 머신비전
- 오픽
- 석사
- 딥러닝
- 파이썬
- 프로그래밍
- Python
- 코딩
- 파이썬gui
- ComputerVision
- 영어
- 초보영어
- 머신러닝
- Vision
- 영어회화
- coding
- 대학원
- opencv
- 4차산업
- C언어
- 인공지능
- 동사
- 3dprinter
- Today
- Total
미래기술연구소
Kalman filter란? 본문
루돌프 칼만이 1960년 대 초 개발한 알고리즘으로
측정치를 바탕으로 선형 역학계의 상태를 추정하는 재귀필터입니다
NASA의 아폴로 프로젝트에서 네비게이션을 개발할때 사용 되었으며,
현재는 GPS, 주가 예측, 날씨 예측, 인구 예측 등 다양한 부분에서 사용되고 있습니다
기존에 인지하고 있던 과거 측정데이터와 새로운 측정데이터를 사용하여
데이터에 포함된 노이즈를 제거시켜 새로운 결과를 추정(estmate) 하는데 사용하는 알고리즘으로
선형적 움직임을 갖는 대상을 재귀적적용으로 동작시킵니다
추정 이론은 통계학과 신호처리의 한 분야이며,
측정 또는 관찰된 자료에 기반하여 모수(모집단을 대표하는 값) 의 값을 추정하는 것을 다룹니다
예를 들어, 전 세계 인구수를 예측한다고 할 때
전수조사를 하지 않는 이상 모수를 절대 알수 없고, 표본(sample)에서 구한 통계값을 기반으로 모수를
추정하게 되는데 이때, 평균, 표준편차, 분산 등이 모수로 사용됩니다
자연계의 움직임은 어느정도 예측이 가능하며 일반적 움직임 물성을 가지는 것이 당연합니다
누적된 과거데이터와 현재 얻을 수 있는 새로운데이터로 현상태를 추정하고자 하는 것은
우리의 모든 현상에서 요구되는 것임으로 미사일 궤도나 주식의 등락 흐름이나 거의 같습니다
여기서 말하는 필터(filter) 란?
흔히 정수기의 filter를 생각하시면 될 것 같습니다
측정데이타에 포함된 불확실성(noise)을 filtering 하는 것으로
즉, 측정데이터나 신호가 잡음을 동방하는데 여기서 원하는 신호나 정보를 골라내는 알고리즘이라고 보면 됩니다
확률에 기반한 예측시스템이므로 이것의 대상은 정규분포(가우시안분포)를 가지는 대상이 됩니다
가우시안분포 참조
blog.naver.com/msnayana/80107833229
정규분포 vs 6시그마
정규분포 vs 6시그마 세상의 모든 현상이 정규분포형태를 가지지는 않는다. 하지만 우리 일상의 많은 일들(...
blog.naver.com
norman3.github.io/prml/docs/chapter02/3_1.html
3. The Gaussian Distribution [I]
3. The Gaussian Distribution [I] 가우시안 분포는 보통 정규분포(standard distribution)로 알려져있다. 왜냐하면 연속 확률 분포 중 가장 널리 알려진 분포이기 때문이다. 단일 변수 \( x \) 에 대해 가우시안 ��
norman3.github.io
Kalman Filter 의 기본적인 개념은
과거값 , 현재값 을 가지고 재귀적 (recursive) 연산 (data processing) 을 통하여 최적 (optimal) 값을 추적하는 것입니다
실제 응용에 있어서는 시스템이 non linear 이며 noise가 gaussian이 아닌 경우가 많습니다
kalman filter의 변형이 요구되는데 Extended Kalman Filter (EKF) 가 가장 많이 사용 되고 있습니다
EKF 는 선형화 칼만필터 ( Linearized KF ) 와 유사하나 선형화하는 기준점을 계속 갱신해 나간다는 특징을 가지고 있습니다
칼만필터 알고리즘은 다음의 2가지 가정이 갖춰지는 경우에 사용할수 있습니다.
※ 모션 모델과 측정 모델이 linear할 경우
※ 모션 모델과 측정 모델이 Gaussian 분포를 따를 경우
칼만필터는 위 2가지 조건이 갖춰지는 경우에만 사용 할수 있다는 단점이 있습니다
대부분의 실제 시스템은 가우시안 분포를 따르지 않으며 비선형 모델을 포함합니다.
이러한 문제점을 해결한 것이 확장 칼만 필터입니다.
상태 예측(state prediction)과 측정 업데이트(measurement update)를 반복적으로 수행하며
로봇의 현재 위치를 계산합니다.
상태 예측단계는 이전 로봇의 파라미터(위치, 속도 등)와 로봇 모션 입력을 이용해
현재 로봇 파라미터 값을 예측하는 단계이고, 측정 업데이트는 상태 예측단계에서 예측된
현재 로봇의 파라미터 값과 현재 로봇의 위치에서 얻어진 센서 정보를 이용해 현재 로봇 파라미터 값을
업데이트하는 단계입니다.
1차원의 경우
상태 예측
상태 예측 단계에서는 이전 측정 업데이트에서 계산한 확률 분포와 로봇 모션 입력의 확률 분포를 이용해 현재 상태의 분포를 예측합니다. 이 때 확률분포의 평균은 간단히 두 평균을 더한 것이고 확률분포의 분산은 두 분산을 더한 것이 됩니다. 이는 1차원의 경우를 예로 들고 있기 때문에 간단한 합이 되지만 뒤에서 다룰 다차원의 경우에는 좀더 복잡한 수식으로 상태 예측이 수행됩니다.

측정 업데이트
측정 업데이트는 상태 예측단계에서 예측된 현재 로봇 위치에 대한 확률분포와 현재 로봇의 위치에서 측정한 관찰값의 확률 분포를 이용하여 사후 확률분포를 업데이트 하는 방식으로 수행됩니다. 예를 들어 로봇이 이전에 20미터 거리에 있었다고 가정하고 분산은 9미터라고 합시다. 그렇다면 다음과 같은 가우시안 확률 분포를 가집니다.

현재 로봇의 위치에서 측정한 센서의 값은 30미터이고 분산은 3미터라고 하면 다음과 같은 가우시안 분포를 가집니다.

업데이트 된 새로운 가우시안 확률 분포는 이전 가우시안 분포와 measurement의 가우시안 분포의 곱으로 구할수 있습니다. 두 가우시안 분포의 곱에 대한 수식 유도는 좀 복잡해서 따로 링크를 걸어두도록 하겠습니다. 결과적으로 새로운 가우시안 분포의 평균과 분산 값은 아래와 같은 식으로 구할수 있습니다.

이 식을 이용하여 측정 업데이트를 수행하면 아래와 같은 사후 확률분포를 얻을수 있습니다. 이것이 업데이트된 로봇의 위치에 대한 확률분포가 되는 것 입니다.

전체적인 1차원 칼만필터의 측정 업데이트와 상태 예측 단계를 정리하면 아래와 같습니다.
1차원 칼만 필터 정리
칼만필터는 상태 예측과 측정 업데이트의 반복으로 이루어진 알고리즘입니다.
상태 예측 단계에서는 이전 측정 업데이트 단계에서 계산된 로봇의 현재 위치의 확률 분포에 로봇 모션 입력의 확률 분포를 더합니다. 간단히 평균은 평균끼리, 분산은 분산끼리 더하여 새로운 로봇의 현재위치에 대한 확률 분포를 계산합니다.
측정 업데이트 단계에서는 이전 상태 예측 단계에서 예측된 로봇의 현재 위치와 실제 로봇의 현재 위치에서 측정된 관측값을 가중치를 이용해 측정값을 업데이트 합니다. 여기서 가중치는 예측된 로봇의 현재 위치에 대한 분산값과 실제 로봇의 현재 위치에서 측정된 관측값의 분산값에 따라 결정됩니다. 이 가중치는 다차원의 경우에 칼만게인이라는 행렬로 확장됩니다.

다차원 칼만 필터
(사전 숙지) 가우시안 분포의 선형 변환
여기서 우리가 알아야 할 정보는 선형모델에서 가우시안 분포의 변환입니다. 확률변수 X가 가우시안 분포를 따를때, 확률변수 Y가 Y=AX+B와 같은 선형변환으로 이루어지면, 확률변수 Y도 가우시안 분포를 따르며 그 평균과 공분산은 다음과 같습니다.

평균이 저렇게 되는것은 쉽게 이해할수 있으나 공분산의 형태는 쉽게 이해하기 어렵습니다. 이 때 공분산의 수식 유도는 다음과 같습니다.

이와 같은 가우시안 분포의 선형 변환을 이용하여 다차원 칼만필터의 상태 예측 단계를 수행할수 있습니다.
상태 예측

1차원의 상태 예측 단계와 마찬가지로 이전의 로봇 파라미터에 대한 확률 분포에 로봇 모션 입력의 확률 분포를 더해줍니다. 여기서 A는 t시간의 로봇 파라미터와 t-1시간의 로봇 파라미터의 관계를 나타내는 상태 전이 행렬입니다. 그리고 B는 t시간의 로봇 모션 입력과 t시간의 로봇 파라미터의 관계를 나타내는 행렬입니다.
먼저 첫번째줄인 t시간의 로봇 파라미터의 가우시안 분포에 대한 평균값 계산에 대해서 살펴보면 다음과 같습니다. 단순한 두 값의 합산으로 이루어져 있습니다.

다음으로 두번째줄인 t시간의 로봇 파라미터의 가우시안 분포에 대한 공분산 행렬 계산에 대해서 살펴보면 다음과 같습니다. 가우시안 분포를 가지는 확률변수의 공분산 행렬 계산 때 처럼 앞쪽 항이 구해지고 R은 로봇 모션을 방해하는 불확실한 요인에 대한 공분산 행렬(베어링 마찰이나 편심질량, 공기저항)과 더해서 최종 값이 계산되게 됩니다.

이 식을 통해 1차원 상태 예측 단계 처럼 로봇에 대한 파라미터 상태를 예측할수 있습니다.
측정 업데이트
1차원의 측정 업데이트 단계와 마찬가지로 이전 상태 예측 단계에서 예측된 로봇의 파라미터값과 현재 로봇의 상태에서 측정한 파라미터 값사이를 가중치를 이용해 측정값을 업데이트 합니다. 여기서 가중치는 칼만게인으로 정의 되며 K로 나타냅니다. 1차원의 경우에는 분산의 비율로 가중치를 정했는데 다차원의 경우 칼만 게인은 좀 더 복잡한 수식으로 구해집니다. 본 문서에서는 칼만게인의 수식 유도는 다루지 않고 칼만 필터의 전체 과정만을 다룹니다. C는 현재 로봇 파라미터와 관측된 로봇 파라미터값 사이의 상관관계를 나타내는 행렬이며 Q는 관찰값의 공분산 입니다.
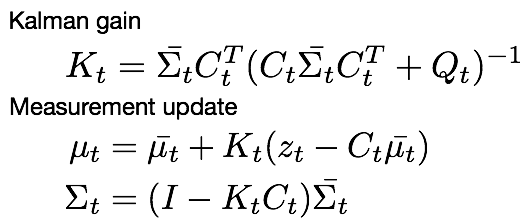
칼만 게인을 구하고 나면 로봇의 파라미터 값을 업데이트 해줍니다. 여기서는 관찰된 데이터와 상태 예측 단계에서 얻은 로봇 파라미터의 예측값에서 기대되는 관측값과의 차이를 칼만 게인을 가중치로 하여 얻은 크기만큼 더해주어서 최종적인 로봇 파라미터 확률분포를 업데이트 합니다.
전체적인 다차원 칼만필터의 측정 업데이트와 상태 예측 단계를 정리하면 아래와 같습니다.

결과 분석
예를 들어 관찰값에 대한 공분산인 Q가 무한대 즉, 측정 값이 전혀 신뢰할수 없는 경우를 생각해봅시다. 그러면 칼만 게인 값은 0이 됩니다. 따라서 예측된 로봇의 위치를 그대로 가져다 씁니다.

반대로 Q가 0인 경우 즉 측정값이 아주 신뢰도가 높은 경우를 생각해봅시다. 그러면 z값만 남게되어 측정값을 그대로 가져다 씁니다.
< 출 처 >
blog.naver.com/msnayana/80106682874
medium.com/@celinachild/kalman-filter-소개-395c2016b4d6
'Industry 4.0 > Control Engineering' 카테고리의 다른 글
| LQR 제어 란 ? (0) | 2020.06.01 |
|---|---|
| Kalman Filter (0) | 2020.06.01 |
| 제어공학 강의자료 (0) | 2020.05.10 |
| PLC 란? PLC가 뭐야? (0) | 2020.05.07 |
| Automatic control (0) | 2020.04.14 |


