
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 특수대학원
- 오픽
- 영어회화
- 영어기초
- 동사
- 파이썬
- 머신비전
- 4차산업
- C언어
- 코딩
- 딥러닝
- 대학원
- 파이썬gui
- 직장인
- 영어
- 인공지능
- coding
- 산업대학원
- 석사
- 프로그래밍
- 초보영어
- Python
- opencv
- 영어공부
- 3dprinter
- Vision
- ComputerVision
- machinevision
- 머신러닝
- Ai
- Today
- Total
미래기술연구소
A Real time unoccupied object detection through Background Modeling 본문
A Real time unoccupied object detection through Background Modeling
I s a a c 2020. 7. 6. 16:54A Real time unoccupied object detection through Background Modeling
*Muhammad Adeel Altaf
School of Electronics Engineering
Kyungpook National University
Daegu, South Korea
adeel_farukh3@hotmail.com
큐
queue
리스트의 한쪽 끝에서만 삽입과 삭제가 일어나는 스택과는 달리 리스트의 한쪽 끝에서는 원소들이 삭제되고 반대쪽 끝에서는 원소들의 삽입만 가능하게 만든 순서화된 리스트. 가장 먼저 리스트에 삽입된 원소가 가장 먼저 삭제되므로 선입 선출(先入先出)인 FIFO(first in first out) 리스트라고 한다.

Abstract
— A technique is required to detect the unoccupied objects from surveillance video.
감시 비디오에서 비어 있는 물체를 감지하는 기술이 필요합니다.
The method utilizes a Background modeling algorithm and identifies any static object lying unoccupied for a specific period of time.
이 방법은 백그라운드 모델링 알고리즘을 사용하며 특정 시간 동안 비어 있는 정적 객체를 식별합니다.
At first, with the help of Background Subtraction, foreground objects are extracted.
처음에는 BackgroundSubtraction(배경분리) 을 통해 전경 객체가 추출됩니다.
Background Modeling is used through running average-based method.
백그라운드 모델링은 실행 평균기반 방법을 통해 사용됩니다.
In the second step, static objects of foreground objects of consecutive frames are detected.
두번째 단계에서 연속된 프레임의 전경 개체의 정적 개체가 감지된 개체가 감지됩니다.
Experimental results identify that proposed algorithm is efficient for real time video surveillance which is tested on ABODA datasets.
제안된 알고리즘이 ABODA 데이터 세트에서 테스트 된 실시간 비디오 감시에 효율적이라는 실험 결과가 나왔다.
The approach uses a FIFO queue for each pixel in a video frame as an essential element with applying processing method.
이 접근 방식에서는 처리 방법을 적용하여 비디오 프레임의 각 픽셀에 대해 FIFO 대기 열을 필수 요소로 사용합니다.
The pixels of moving objects are visible but they cannot store in the queue.
이동하는 개체의 픽셀을 볼 수 있지만 대기 열에 저장할 수 없습니다.
In the last, static objects can also be further classified into human and non-human objects with the help of edge-based object recognition approach.
마지막으로, 정적인 물체는 가장자리 기반의 물체 인식 접근법의 도움을 받아 인간과 인간이 아닌 물체로 더욱 분류될 수 있습니다.
The technique successfully detects abandoned objects of different sizes present in the video.
이 기술은 비디오에 존재하는 다양한 크기의 버려진 물체를 성공적으로 감지합니다.
Keywords—Abandoned object detection, Video surveillance, Background Subtraction
키 저장소-Abandoned 객체 탐지, 비디오 감시, 백그라운드 감산
I. INTRODUCTION
It is becoming a global problem that suspicious activities are emerging everywhere.
곳곳에서 수상한 활동이 나타나고 있는 것은 세계적인 문제가 되고 있다.
It is needed to identify those things such as if someone comes in gathered areas like railway stations, bus stations or even airports and leaves a bag in public places, it may be contained some explosive material.
철도역, 버스정류장, 공항 등 사람이 모여 있는 곳에 와서 공공장소에 가방을 두고 오면 폭발성 물질이 들어 있을 수 있다는 등의 식별이 필요하다.
To detect the abandoned luggage, an intelligent system is required which can detect the unoccupied objects from a gathering environment as well as it can report to the relevant security staff to avoid the incidents with the help of a sound producing alarm.
버려진 짐을 감지하기 위해서는 집집마다 사람이 살지 않는 물건을 감지할 수 있는 지능형 시스템은 물론, 음향 발생 경보기의 도움을 받아 해당 보안요원에게 신고해 사고를 피할 수 있도록 해야 한다.
It is always considered, especially in rural area, as a quite difficult task to watch the activities all the time in public areas with the help of Closed-Circuit Television (CCTV) cameras.
특히 농촌에서는 폐쇄회로텔레비전(CCTV) 카메라의 도움으로 공공장소에서 항상 활동을 지켜보는 것이 상당히 어려운 작업으로 항상 고려되고 있다.
If somebody leaves its luggage anywhere, it is risky to avoid those things for a long time unoccupied.
만약 누군가가 짐을 아무 곳에나 놓아둔다면, 그러한 것들을 오랫동안 빈손으로 피하는 것은 위험하다.
However, the current surveillance system is a man-powered, where a security guard must have to constantly watch the cameras all the time, throughout the area to find anything suspicious activity.
그러나 현재의 감시체계는 사람이 운전하는 것으로서, 경비원이 의심스러운 활동을 발견하기 위해서는 항상 카메라를 항상 감시해야 한다.
It looks easy but it is not to keep your eyes on the screen for hours.
보기에는 쉬워 보이지만 몇 시간 동안 화면을 주시하지 않는 것이다.
And most probably, he may miss any criminal activity by looking here and there.
그리고 아마 그는 이곳저곳을 둘러보면 어떤 범죄행위도 놓칠지도 모른다.
Several alternatives are presented to solve this problem.
이 문제를 해결하기 위한 몇 가지 대안이 제시되어 있다.
High resolution overhead cameras are used for surveillance in significant locations such as official places or private establishments, to detect such unattended objects of even small size.
고해상도 오버헤드 카메라는 심지어 작은 크기의 이러한 무인 물체를 감지하기 위해 공식적인 장소나 개인 시설과 같은 중요한 장소에서 감시하는데 사용된다.
Although, these cameras are costly, and even with their resolution, there is no guarantee that the security personnel will spot the object.
비록 이 카메라들은 비용이 많이 들고, 심지어 해상도에도 불구하고, 보안요원이 그 물체를 발견한다는 보장은 없다.
In some cases, security officers often patrol the area under surveillance, to maintain vigilance over any such object. This is commonly seen in railway stations and areas of high-security zones. However, this tactic requires excessive manpower, especially if the area under surveillance is huge.
어떤 경우에는 보안요원들이 감시하에 그 지역을 순찰하는 경우가 많은데, 그 어떤 물건에 대해서도 경계를 늦추지 않는다. 이는 철도역 및 보안이 높은 지역의 지역에서 흔히 볼 수 있다. 그러나 이 전술은 특히 감시 대상 지역이 넓을 경우 과도한 인력을 필요로 한다.
Also, if there happens to be a bomb concealed in an abandoned object, this raises the risk of physical harm to the officers who would examine this object.
또한, 만약 버려진 물체에 폭탄이 숨겨져 있다면, 이것은 이 물체를 검사할 경찰관들에게 신체적 해를 끼칠 위험을 높인다.
It is also necessary to educate the people that as they notice any unoccupied object anywhere, it’s their responsibility to raise and discuss the issue with the officials immediately.
아무데서나 비어 있는 물건을 눈치채고 있으니, 즉시 그 문제를 제기하고 당국자들과 상의하는 것이 자신의 책임이라는 것도 국민교육이 필요하다.
Through advertisements on the TV channels or the social media, humans can be motivated to identify such incidents for their safety.
TV 채널이나 소셜 미디어의 광고를 통해 인간은 안전을 위해 그러한 사건들을 식별하도록 동기를 부여받을 수 있다.
As a matter of fact, people ignore such type of instructions and mind their own business.
사실, 사람들은 그런 종류의 지시를 무시하고 그들 자신의 일에 신경을 쓴다.
In fact, if there is a real case that someone finds a bag, he himself feels awkward to inform the security officials.
실제로 누군가 가방을 찾는 진짜 사례가 있으면 그 자신도 경비 관계자들에게 알리기가 어색하다.
So, in these circumstances, it is needed to build an autonomous system which acts intelligently under these conditions.
따라서 이러한 상황에서는 이러한 조건에서 지능적으로 작용하는 자율적인 시스템을 구축할 필요가 있다.
The proposed method takes a video stream as an input and models a static frame as a reference in which other subjects are supposed as ordinarily present in it.
제안된 방법은 비디오 스트림을 입력으로 사용하고 정적 프레임을 다른 피험자가 일반적으로 존재하는 것으로 간주되는 참조로 모델링한다.
First, it does background subtraction to find out the foreground objects. Then it updates the background in which the object that has changed its original position or any new object comes into its coverage are of region that has been abandoned. At last, it compares the new background with the original frame which contains the unoccupied object in its new window.
첫째, 배경 감산을 통해 전경의 물체를 알아낸다. 그런 다음 원래 위치를 변경하거나 새로운 개체를 적용 범위에 포함시키는 개체의 배경을 업데이트한다. 마침내, 그것은 새로운 배경과 새로운 창에 비어있는 물체가 들어 있는 원래의 프레임을 비교한다.
II. PROPOSED FRAMEWORK
II. 제안된 프레임워크
Several methods have been previously proposed for the detection of abandoned objects.
In [1], Miguel et al. fused three features based on shape and color information to detect unattended or stolen objects. Jing Chang [2] utilizes selective tracking to determine whether the owner of the so detected abandoned luggage is in proximity by detecting “skin color information” and body contours. However, it is difficult to determine in crowded situations where people are rapidly moving towards and away from the luggage.
버려진 물체의 탐지를 위한 몇 가지 방법이 이전에 제안된 바 있다.
[1]에서는 미겔 외 연구진이다. 모양과 색상 정보를 기반으로 세 가지 기능을 융합하여 무인 또는 도난 물체를 감지할 수 있다. 징창[2]은 선별적 추적을 활용하여 이렇게 발견된 버려진 짐의 주인이 '피부색 정보'와 차체 윤곽선을 감지하여 근접 여부를 판단한다. 그러나 사람들이 짐을 빠르게 오가는 혼잡한 상황에서는 판단하기 어렵다.
Also, detecting such object of a person is subject to lighting changes and occlusions due to a crowded environment. Most of the proposed methods, such as the one proposed by M. Bhargava [15] search for an owner of the luggage in the midst of the crowd, which requires the system to have a lot of memory at its disposal. Fan et al. [13] proposed a system to detect large abandoned object with low false positive rates. Background Subtraction [7] is also commonly utilized, but it is a practical only if the background so acquired updates itself with lighting changes over time, to prevent noise contours.
또한 사람이 그러한 대상을 탐지하는 것은 사람이 붐비는 환경으로 인해 조명 변화와 혼선을 겪게 된다. M이 제안한 방법 등 제안하는 방법의 대부분은 다음과 같다. 바르가바[15]는 군중들 틈에서 짐의 주인을 찾아다닌다. 이것은 시스템이 마음대로 많은 기억을 가질 것을 요구한다. 팬 외 [13] 거짓 양성률이 낮은 대형 버려진 물체를 탐지하는 시스템을 제안했다. Background Subtraction[7]도 일반적으로 활용되지만, 그렇게 획득한 배경이 시간이 지남에 따라 조명으로 스스로 업데이트되어 소음 등고선을 방지해야 실용적이다.
Gaussian Mixture Model (GMM) is commonly utilized to achieve background updating [12] [3] [10]. Although GMM is an efficient method for background modeling but it is memory intensive. So, it is needed to present a memory efficient algorithm to achieve a result that is comparable to that of GMM
Gaussian Mixture Model (GMM)은 일반적으로 백그라운드 업데이트를 달성하기 위해 사용된다 [12] [3] [10]. GMM은 백그라운드 모델링을 위한 효율적인 방법이지만 메모리 집약적이다. 따라서 GMM에 버금가는 결과를 얻기 위해서는 메모리 효율 알고리즘을 제시할 필요가 있다.
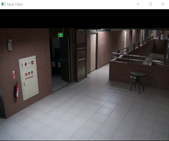

그림 1: 정적 프레임- 물체가 없는 I 및 물체가 있는 II
A. Defining Reference Static Objects Frame
This approach assumes during the preprocessing step where it considers that there are no any unoccupied objects in the ‘n’ frames of the video. So, in order to make an initial static background from the input video, it contains only those objects which are at rest position. The composition of static objects is stool, fire extinguisher, electric board, alarm system and so on. It is done by using the average value of each pixel in the first ‘n’ frames making an image. It is computed just like the design flow of the algorithm within seconds and is capable to store its static background in its memory as well.
A. 기준 정적 객체 프레임 정의
이 접근방식은 비디오의 'n' 프레임에 빈 객체가 없다고 간주하는 사전 처리 단계에서 가정한다. 그래서, 입력 비디오로부터 초기 정적 배경을 만들기 위해서, 그것은 정지 위치에 있는 물체만을 포함한다. 정적 물체의 구성은 대변, 소화기, 전기 보드, 경보 시스템 등이다. 첫 번째 'n' 프레임에서 각 픽셀의 평균값을 사용하여 이미지를 만드는 것이다. 수 초 내에 알고리즘의 설계 흐름과 마찬가지로 계산되며, 정적 배경도 메모리에 저장할 수 있다.
B. Upgrading Current Static Framework
As the preprocessing is done with the help of static objects in the background that are usually present in such type of videos, it is definitely needed to update the previously defined computations and make a model of an upgraded static background. So, this is done after the desired time interval by incorporating with the new incoming static objects in the input video. Moreover, if a camera detects a new object within its defined range and it does not change its position with certain time period, it can be seen in the upgraded static background. In the situation, it will still work even if the object is not cleared due to the low resolution of the video. Although, the speedily moving objects have a low impact while upgrading the static background, so this updating background is unaffected by object occlusion due to the crowds. It is also helpful in detecting the objects in the presence of temporal as well as spatial occlusion.
B. 현재 정적 프레임워크 업그레이드
사전 처리는 그러한 종류의 비디오에 주로 존재하는 배경의 정적 객체의 도움으로 이루어지기 때문에, 이전에 정의된 계산을 업데이트하고 업그레이드된 정적 배경의 모델을 만드는 것이 반드시 필요하다. 따라서 이 작업은 입력 비디오에서 새로 들어오는 정적 객체와 통합하여 원하는 시간 간격 후에 수행된다. 더구나 카메라가 정해진 범위 내에서 새로운 물체를 감지하고 일정 기간 동안 위치를 바꾸지 않으면 업그레이드된 정적 배경에서 이를 볼 수 있다. 상황이 이렇다 보니 영상의 해상도가 낮아 물체를 치우지 않아도 여전히 작동한다. 비록 빠르게 움직이는 물체는 정적 배경을 업그레이드하는 동안 영향이 적지만, 이 업데이트 배경은 군중으로 인한 물체 방해의 영향을 받지 않는다. 또한 공간적 폐색뿐만 아니라 시간적 폐색 상태에서도 사물을 탐지하는 데에도 도움이 된다.
C. Frames Comparison
It can be considered that if any object is not detected in the video feed for an extended time period, its presence can be visible in the upgraded static frame. This updated frame is compared with the previous ones without having the object, such comparison is performed by calculating a difference between both frames.
C. 프레임 비교
장기간 비디오 피드에서 어떤 물체도 감지되지 않으면 업그레이드된 정적 프레임에서 그 존재감을 볼 수 있다고 생각할 수 있다. 이 업데이트된 프레임을 오브젝트 없이 이전 프레임과 비교하며, 이러한 비교는 두 프레임의 차이를 계산하여 수행된다.
D. Classify into human and Non-human objects
By using edge-based object recognition approach, it can be categorized the objects into human and non-human static object. This algorithm basically uses edge information of an object into a human edge-based sample [14]. After the matching-template generated of static object with the pre-defined sample of human edges, Template matching is performed to generate a score. So, this generated score classifies the static objects into human and non-human objects. In this regard, Edge-based Object Feature and Template matching score generation steps are performed to produce the matching score between the predefined human-based template and the detected static object.
D. 인간과 인간이 아닌 물체로 분류
엣지 기반 객체 인식 접근법을 사용하여, 그것은 그 물체를 인간과 인간이 아닌 정적 물체로 분류할 수 있다. 이 알고리즘은 기본적으로 인간의 가장자리 기반 샘플에 물체의 가장자리 정보를 사용한다[14]. 정적 객체의 생성과 인간 가장자리의 사전 정의된 샘플이 일치된 후에 Template 일치를 수행하여 점수를 생성한다. 그래서, 이 생성된 점수는 정적인 물체를 인간과 인간이 아닌 물체로 분류한다. 이와 관련하여 Edge 기반 Object Feature 및 Template 일치 점수 생성 단계를 수행하여 미리 정의된 인간 기반 템플릿과 탐지된 정적 객체 간에 일치하는 점수를 생성한다.

그림 2. 픽셀 기반 백그라운드 모델링 객체 탐지
V. MATHEMATICAL PRESENTATION
Consider the nth frame of the video as In, such that In (i, j) represents the value of pixel present at ith row and jth column of nth frame. For each such pixel value a queue Q (i, j) of size N, a sum of pixel values S (i, j) and average of pixel values A (i, j) is maintained over the incoming frames. The total number of frames N to be considered for modeling a static background so, it can be selected by user as per the requirement. It is directly related to the measure of time after which an object will be declared abandoned. Starting from the first frame, n = 1:
V. 수학 프레젠테이션
비디오의 n번째 프레임을 In (i, j)은 ith 행에 존재하는 픽셀 값과 n번째 프레임의 j번째 열을 나타내도록 In으로 간주한다. 그러한 각 픽셀 값에 대해 N 크기의 큐 Q(i, j)와 픽셀 값 S(i, j)의 합과 픽셀 값 A(i, j)의 평균이 들어오는 프레임에 대해 유지된다. 사용자가 요구 사항에 따라 선택할 수 있도록 정적 배경을 모델링하기 위해 고려할 총 프레임 수 N. 그것은 어떤 물체가 버려진 것으로 선언될 때까지의 시간의 척도와 직접적인 관련이 있다. 첫 번째 프레임부터 n = 1:
• If n < N
Q (i, j) = I1(i, j), I2(i, j), ..., In−1 (i, j), In (i, j)
Hence sum of elements of this queue is given by:
따라서 이 대기열의 요소의 합은 다음과 같다.

Average of elements of this queue is given by:
이 대기열 요소의 평균값은 다음과 같다.
An (i, j) = 0
It calculates the average value of each pixel in pixel queue only when first N frames has been observed by system and hence the background frame is blank here.
시스템에서 처음 N 프레임이 관측되어 배경 프레임이 비어 있을 때만 픽셀 대기열에 있는 각 픽셀의 평균값을 계산한다
• If n ≥ N
Q (i, j) = In−N+1(i, j), In−N+2(i, j), ..., In−1(i, j), In (i, j)
Now sum of elements of this queue is given by:
이제 이 대기열의 요소의 합계는 다음과 같다.
Sn (i, j) = Sn−1(i, j) + In (i, j) – Q (i, j). front (3)
where In (i, j) is pixel value in the latest frame and Q (i, j). front is the oldest pixel value in the queue Q (i, j) Average of elements of this queue is given by:
여기서 (i, j)는 최신 프레임에서 픽셀 값이고 Q(i, j)는 Q(i, j)는 큐에서 가장 오래된 픽셀 값이다. 이 큐의 요소의 평균값은 다음과 같다.
An (i, j) = Sn (i, j)/N
Now, model a background such that:
이제 다음과 같은 배경을 모델링하십시오.
[Bn (i, j)] c × d = [An (i, j)] c × d
where c × d is the dimension of the frame and Bn (i, j) is the pixel value in the static background frame. This ensures that it always compute the average of the latest N number of frames coming in the video feed. Hence, for an appropriate value of N, the proposed algorithm automatically updates background. That is why, it simultaneously maintains a separate video frame Wn (i, j) that contains the abandoned objects detected by the algorithm. If there is no any object, this window remains empty.
여기서 c × d는 프레임의 치수, Bn(i, j)은 정적 배경 프레임의 픽셀 값이다. 이렇게 하면 비디오 피드에 들어오는 최신 프레임 수 N개의 평균을 항상 계산할 수 있다. 따라서 N의 적절한 값에 대해 제안된 알고리즘은 자동으로 배경을 업데이트한다. 그 때문에 알고리즘에 의해 검출된 버려진 물체가 포함된 별도의 비디오 프레임 Wn(i, j)을 동시에 유지한다. 물체가 없으면 이 창은 비어 있다.
VI. EXPERIMENTAL RESULTS
In this section, experiments have been performed on the basis of proposed approach on the Abandoned Objects Datasets (ABODA) [16]. This dataset contains 11 videos from different scenarios related with abandoned objects. Since the unoccupied object scene fits this problem, so tested the algorithm on the video sequences that contains abandoned luggage placed on a platform. It can also be compared with the methods with current state-of-the-art studies of [9], [4], [6], [11], [5], [8]. So, the resolution of the input video (dimension) is 640*480 with frame rate of 30fps (frames per second). The execution time is 296 milliseconds per frame for complete program. The program is implemented using the environment of OpenCV 3.0 image processing library on Microsoft Visual Studio 2015 for SW. The processor Intel® Core™ i5-3350P CPU @ 3.10GHz with 8 GB RAM and a graphic card NVIDIA GeForce GTX 650Ti of LG Desktop PC is used for the experiments. The luggage is easily detected as shown in Fig.3 & Fig.6 due to no crowd and large size of luggage.
VI. 실험 결과
이 섹션에서는, 버려진 개체 데이터 세트(ABODA)에 대한 제안된 접근법에 기초하여 실험을 수행하였다[16]. 이 데이터 집합에는 버려진 물체와 관련된 다양한 시나리오의 11개의 비디오가 포함되어 있다. 비어 있는 객체 장면이 이 문제에 적합하기 때문에 플랫폼에 놓여진 버려진 짐이 포함된 비디오 시퀀스에 알고리즘을 테스트했다. 또한 [9], [4], [6], [11], [5], [8]의 최신 연구 방법과도 비교할 수 있다. 따라서 입력 비디오(차원)의 해상도는 640*480이며 프레임률은 30fps(초당 프레임 수)이다. 실행 시간은 전체 프로그램에 대해 프레임당 296밀리초입니다. 이 프로그램은 SW용 Microsoft Visual Studio 2015에 있는 OpenCV 3.0 이미지 처리 라이브러리의 환경을 이용하여 구현된다. 실험에는 8GB RAM이 탑재된 3.10GHz 프로세서 Intel® Core™ i5-3350P CPU와 LG 데스크탑 PC의 그래픽 카드 NVIDIA GeForce GTX 650Ti가 사용된다. 짐은 사람이 많지 않고 큰 크기의 짐으로 인해 그림 3 & 그림 6과 같이 쉽게 감지된다.
TABLE I. ABANDONED OBJECT DATASETS (ABODA)
표 I. 폐기된 개체 데이터 집합(ABODA)
|
Dataset |
Performance Evaluation |
||||
|
No. of video sequences |
Abandoned Object Detection |
Not Detected Object |
Detection Rate (%) |
Object detected with some errors |
|
|
ABODA |
11 |
10 |
01 |
90.90 |
9% |
|
|
Average Detection Rate 91 % |
||||
Table I explains that the average detection rate of the system is 91%. To evaluate the performance of the system, 10 videos sequences have been used from which some of the results are shown below. The scenes consist of change in lighting conditions, illumination effects, occlusion, nigh-time detection, indoor as well as outdoor environments, and varying the size of left luggage. Remarkably, this method satisfies the abandoned object in all these different conditions.
표 I는 시스템의 평균 검출률이 91%라고 설명한다. 시스템의 성능을 평가하기 위해 10개의 비디오 시퀀스를 사용했으며, 그 결과 중 일부는 아래와 같다. 장면들은 조명 조건의 변화, 조명 효과, 폐색, 근시 감지, 실내 및 실외 환경, 그리고 왼쪽 짐의 크기 변화로 구성되어 있다. 놀랍게도, 이 방법은 이 모든 다른 조건에서 버려진 물체를 만족시킨다.



그림.3: 시퀀스의 검출 결과

그림.4: 섀도잉 효과를 이용한 폐쇄 테스트

그림.5: 조명 변화를 통한 폐쇄 테스트

그림.6: 버려진 물체가 감지됨
Occlusion in object detection algorithm does play an important role so, the temporal and spatial occlusion conditions are created during testing the algorithm. There may be objects of different dimensions and a variable distance from the camera so, that situation can also be created for testing.
물체 감지 알고리즘의 폐쇄는 중요한 역할을 하므로 알고리즘을 테스트하는 동안 시간적 공간적 폐색 조건이 생성된다. 다른 치수의 물체와 카메라로부터 가변적인 거리가 있을 수 있으므로 시험을 위한 상황도 조성될 수 있다.
VII. CONCLUSION
The patch of the pixels that remain static for a certain time period (set by threshold) is considered as Abandoned objects. The program stores the pixels of incoming new object in the queue. The pixels which move their position, this algorithm continuously pop those pixels until the pixels remain static for a specific time, then save in the queue. Edge-based recognition for objects approach is used in categorizing into human and non-human static objects. That is why unoccupied objects are detected in a real time and this is done with the help of Background modeling. The main advantage of this technique is that it is not affected due to Occlusions.
VII. 결론
일정 기간(임계값으로 설정) 동안 정적으로 유지되는 픽셀의 패치는 포기된 개체로 간주된다. 프로그램은 들어오는 새 개체의 픽셀을 대기열에 저장한다. 위치를 이동하는 픽셀, 이 알고리즘은 픽셀이 특정 시간 동안 정적인 상태를 유지할 때까지 해당 픽셀을 계속 팝업한 다음 큐에 저장한다. 물체 접근에 대한 가장자리 기반 인식은 인간과 인간이 아닌 정적 물체로 분류하는 데 사용된다. 그렇기 때문에 빈 객체가 실시간으로 감지되며 이는 백그라운드 모델링의 도움을 받아 이루어진다. 이 기법의 가장 큰 장점은 오클로스 때문에 영향을 받지 않는다는 것이다.
VIII. FUTURE WORK
This algorithm can be implemented on FPGA boards like Xilinx Zynq-7020 all programmable system on chip because it has processing system that contains dual ARM Cortex-A9 MP-Core processor that provides high speed sequential logic implementations and a powerful programmable logic that also contains Artix-7 FPGA with 85k logic cells. So, a chip can be embedded on the developed FPGA board in the form of a Hardware in the future.
VIII. 미래 작업
이 알고리즘은 고속 순차 로직 구현을 제공하는 듀얼 ARM Cortex-A9 MP-Core 프로세서를 탑재한 프로세싱 시스템과 85k 로직 셀을 탑재한 아틱스-7 FPGA도 탑재한 강력한 프로그램 가능 로직을 탑재하고 있어 칩 상의 모든 프로그래밍 가능한 시스템인 Xilinx Zynq-7020과 같은 FPGA 보드에서 구현할 수 있다. 그래서 향후 개발된 FPGA 보드에 하드웨어 형태로 칩을 내장할 수 있다.
REFERENCES
[1] J. C. S. Miguel and J. M. Martinez, “Robust unattended and stolen object detection by fusing simple algorithms,” In proceedings of IEEE Fifth International Conference on Advanced Video and Signal Based Surveillance, pp. 18-25, 2008.
[2] J.-Y. Chang, H.-H. Liao, and L.-G. Chen. Localized detection of abandoned luggage. EURASIP Journal on Advances in Signal Processing, 2010(1):1–9, 2010.
[3] Y. Dedeoglu. Human action recognition using gaussian mixture model˘ based background segmentation.
[4] R. H. Evangelio, T. Senst, and T. Sikora. Detection of static objects for the task of video surveillance. In Applications of Computer Vision (WACV), 2011 IEEE Workshop on, pages 534–540. IEEE, 2011.
[5] Q. Fan, P. Gabbur, and S. Pankanti. Relative attributes for large-scale abandoned object detection. In Proceedings of the IEEE International Conference on Computer Vision, pages 2736–2743, 2013.
[6] Q. Fan and S. Pankanti. Modeling of temporarily static objects for robust abandoned object detection in urban surveillance. In Advanced Video and Signal-Based Surveillance (AVSS), 2011 8th IEEE International Conference on, pages 36–41. IEEE, 2011.
[7] H. Lee, S. Hong, and E. Kim. Probabilistic background subtraction in a video-based recognition system. KSII Transactions on Internet & Information Systems, 5(4), 2011.
[8] H.-H. Liao, J.-Y. Chang, and L.-G. Chen. A localized approach to abandoned luggage detection with foreground-mask sampling. In Advanced Video and Signal Based Surveillance, 2008. AVSS’08. IEEE Fifth International Conference on, pages 132–139. IEEE, 2008.
[9] F. Porikli, Y. Ivanov, and T. Haga. Robust abandoned object detection using dual foregrounds. EURASIP Journal on Advances in Sign Processing, 2008(1):1–11, 2007.
[10] C. Stauffer and W. E. L. Grimson. Adaptive background mixture models for real-time tracking. In Computer Vision and Pattern Recognition,
[11] 1999. IEEE Computer Society Conference on., volume 2. IEEE, 1999.
[12] Y. Tian, R. S. Feris, H. Liu, A. Hampapur, and M.-T. Sun. Robust detection of abandoned and removed objects in complex surveillance videos. Systems, Man, and Cybernetics, Part C: Applications and Reviews, IEEE Transactions on, 41(5):565–576, 2011.
[13] Q. Fan and S. Pankanti, “Robust foreground and abandonment analysis for large scale abandoned object detection in complex surveillance videos,” In proceedings of IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance, pp. 58-63, 2012.
[14] P.K. Shiju, “Edge based Template Matching,”, CPOL, 2010.
[15] M. Bhargava, C.-C. Chen, M. S. Ryoo, and J. K. Aggarwal. Detection of object abandonment using temporal logic. Machine Vision and Applications, 20(5):271–281, 2009.
참고 자료
[1] J. C. S. 미구엘과 J. M. 마르티네즈, "단순 알고리즘을 융합하여 물체 탐지 및 도난 방지" IEEE 제5차 고급 비디오 및 신호 기반 감시에 관한 국제 컨퍼런스 진행 중, 페이지 18-25.
[2] J.-Y. 장, H.H.랴오, L.G. 첸, 버려진 짐의 현지 발견 2010년 (1:9, 2010) 신호 처리 진보에 관한 EURASIP 저널.
[3] Y. 디데오글루. 가우스 혼합물 모델을 사용한 휴먼 액션 인식 기반 배경 분할.
[4] R. H. 에반젤리오, T. 센스트, T. Senst, T. 시코라 입니다 비디오 감시 작업을 위한 정적 물체 탐지. 컴퓨터 비전(WACV), 2011 IEEE 워크샵의 534~540페이지. IEEE, 2011.
[5] Q. 팬, P. 가브르, S. 판칸티. 대규모 버려진 객체 탐지를 위한 상대 속성. 컴퓨터 비전에 관한 IEEE 국제 회의의 절차에서, 2013년 페이지 2736–2743.
[6] Q. 팬과 S. 판칸티. 도시 감시에서 강력한 버려진 물체 탐지를 위한 임시 정적 물체 모델링. AVSS(Advanced Video and Signal-Based Surveillance), 2011년 8차 IEEE 국제 컨퍼런스(36-41페이지) IEEE, 2011.
[7] H. Lee, S. 홍, E. Kim. 비디오 기반 인식 시스템에서 확률적 배경 감산. KSII Transactions on Internet & Information Systems, 2011년 5월 4일.
[8] H.H.랴오, J.Y. 창이랑 L.G. 첸. 포그라운드-마스크 샘플링으로 버려진 짐 찾기에 대한 국부적 접근법. 고급 비디오 및 신호 기반 보안 감시, 2008. AVSS'08. IEEE 제5차 국제 회의 132-139페이지. IEEE, 2008.
[9] F. 포리클리, Y. 이바노프, 그리고 T. Haga. 이중 전경을 사용한 강력한 버려진 물체 감지. EURASIP Journal on Advance in Sign Processing, 2008(1:1):1–11, 2007.
[10] C. Stauffer와 W. E. L. Grimson. 실시간 추적을 위한 적응형 백그라운드 혼합물 모델. 컴퓨터 비전과 패턴 인식에서,
[11] 1999. IEEE 컴퓨터 협회 회의, 제2권 IEEE, 1999.
[12] Y. Tian, R. S. Feris, H. 류, A. 함파푸르, 그리고 M.-T. Sun. 복잡한 감시 영상에서 버려지고 제거된 물체의 강력한 검출. 시스템, Man 및 Cybernetics, Part C: Applications and Reviews, IEEE Transactions on, 41(5):565–576, 2011.
[13] Q. 팬과 S. 판칸티, "복합 감시 영상에서 대규모 버려진 물체 탐지를 위한 확실한 전경과 포기 분석" 58-63, 2012페이지의 IEEE 제9차 고급 비디오 및 신호 기반 감시 국제회의 진행 중.
[14] P.K. Siju, "Edge based Template Matching", CPOL, 2010.
[15] M. Bhargava, C.-C. Chen, M. S. 류, J. K. Aggarwal. 시간 논리를 사용한 객체 포기 감지. 기계 비전과 애플리케이션, 20(5):271–281, 2009.
github.com/kevinlin311tw/ABODA
kevinlin311tw/ABODA
Abandoned Object Dataset. Contribute to kevinlin311tw/ABODA development by creating an account on GitHub.
github.com
A. Testing is made on Indoor video sequences.
A. 실내 비디오 시퀀스에 대한 테스트를 실시한다.

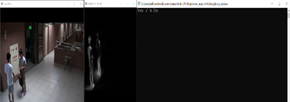
1. 정적 프레임 획득 단계 정적 프레임 획득 완료

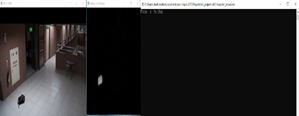
2. 공간적 폐색 테스트 버려진 물체가 검출됨
B. Outdoor video sequences are used to test the program in different positioning the object.
B. 실외 비디오 시퀀스는 물체를 다른 위치에 놓고 프로그램을 테스트하기 위해 사용된다.


3. 초기 정적 프레임 획득 상태 객체를 떠나는 것 픽셀 캡처


4. 짐을 맡겼다 탐지된 개체 보안에서 개체를 찾음


5. 객체의 위치 조정 물체 탐지
C. Illumination effects with Temporal and spatial occlusion testing on the sequences given below
C. 아래 주어진 순서에 대한 시간적 및 공간적 폐색 시험에 의한 조명 효과


6. 시간적 폐색 장애물이 감지되면 폐색이 영향을 미치지 않음


7. 물체 탐지 일정 시간 동안 조명 효과
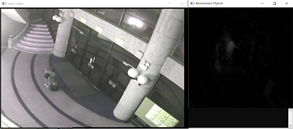

8. 객체 위치 조정 백그라운드 업데이트 후 개체 탐지


9. 참조 정적 프레임 획득 조명은 얼마간 영향을 미친다

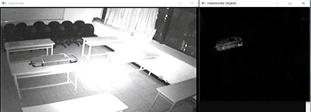
10. 물체가 누군가에 의해 배치되고 있다. 물체 탐지
'Foundation > 논문 뜯어보기' 카테고리의 다른 글
| EGC (0) | 2020.07.16 |
|---|---|
| 논문 47p, 공정 불량현황 패턴분석 (0) | 2020.07.03 |
| 소결이란? (0) | 2020.06.29 |
| 전기로 (0) | 2020.06.27 |


