
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 코딩
- ComputerVision
- 산업대학원
- C언어
- Vision
- coding
- 파이썬
- 동사
- 머신비전
- 프로그래밍
- 석사
- 인공지능
- 3dprinter
- 직장인
- 대학원
- 영어공부
- Python
- 오픽
- 4차산업
- Ai
- 영어
- 머신러닝
- 영어기초
- 파이썬gui
- machinevision
- opencv
- 딥러닝
- 특수대학원
- 초보영어
- 영어회화
- Today
- Total
미래기술연구소
영상 인식 알고리즘을 이용한 안전 보호구(안전모) 탐지에 관한 연구 본문
영상 인식 알고리즘을 이용한 안전 보호구(안전모) 탐지에 관한 연구
A Study on Safety Helmet Detection Using Image Recognition Algorithm
Chun-myoung Noh1, Ki-Kwan Kim1, Su-bong Lee2, Dong-hoon Kang1, and Jae-chul Lee1† 1Dept. of Ocean System Engineering, Gyeongsang Nat’l Univ., Republic of Korea 2ADIALab, Pusan, Republic of Korea
Received 30 March 2020; received in revised form 1 June 2020; accepted 30 November 2020
ABSTRACT
Safety accidents at work sites are directly related to workers' lives, and the manufacturing indus try's interest in safety accidents is increasing every year. Safety accidents at work sites are caused by a variety of factors, and it is difficult to predict when and why they occur. In this research, an intelligent image recognition-based worker safety protection device wearing algo rithm that can determine suitability of wearing safety protective devices is developed and the proposed algorithm is sought to be applied to the site. In this study, the You only look once (YOLO) algorithm is applied to analyze the presence of workers wearing safety protection equipment in real time. Accuracy of object detection for safety protection equipment is very important. Thus, this study compared/analyzed the algorithms of two YOLO systems (YOLOv2, YOLOV3) and improved the performance of the model by changing Hyperparameters, Fine-tun ing and Dataset of the selected algorithms. In the future, studies will be conducted on how to improve the accuracy of object detection and complement the accuracy of object detection in the proposed YOLO series algorithm.
Key Words: Object detection, Real-time detection, Safety protection
1. 서 론
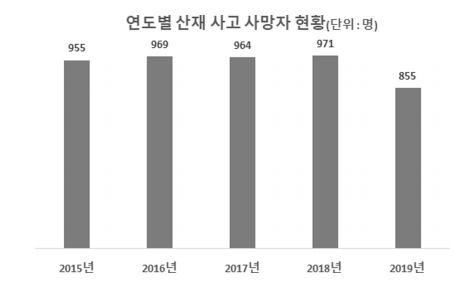
제조 산업의 작업현장에서는 매년 안전사고가 발생하고 있으며, 2015년 이후로 안전사고로 인한 사망자도 800명 이상이 된다(Fig. 1). 작업장에서 의 안전사고는 작업자의 생명과 직접적인 연관이 있기 때문에 작업장내 안전사고를 예방할 수 있는 방법에 대한 연구는 제조산업에서 중요한 과제 중 하나이다.
안전사고는 다양한 요인(환경적 · 인적 · 기계적 요인)에 의해 발생한다. 환경적 요인으로는 작업 현장 내에 안전성이 확보되지 못하거나 혼잡한 경 우 발생하고, 인적 요인은 부적합한 도구 사용이 나 안전 보호구를 착용하지 않았을 경우, 마지막 으로 기계적 요인으로는 기계가 노후가 되었거나 목적에 맞지 않게 사용되었을 경우에 안전사고가 발생하게 된다. 본 연구에서는 여러 사고 요인들 중 인적 요인에 중점을 두고 연구를 진행했다.
인적 요인으로 인한 안전 사고 예방은 작업현장에서 작업자들이 안전 사고 예방을 위해 작업자의 신체를 보호할 안전 보호구 착용이 우선이다. 안전 보호구는 여러 종류가 존재하고 상황 별 착용하는 보호구가 다르지만 본 연구에서는 작업현장에서 공통적으로 착용하는 헬멧을 안전 보호구로 한정하여 진행한다.
본 연구에서는 객체 탐지를 위한 알고리즘들 중 실시간으로 영상을 처리하여 목표로 하는 객체를 찾을 수 있도록 하는 알고리즘들에 대해 중점을 두고 분석했다. 이후에는 안전 보호구 이미지 데이터를 이용하여 알고리즘 모델에 대해 학습을 진행하고 성능을 비교한다. 그리고 촬영된 동영상에 적용하여 학습한 모델의 객체 인식 성능을 영상으로 파악한다.
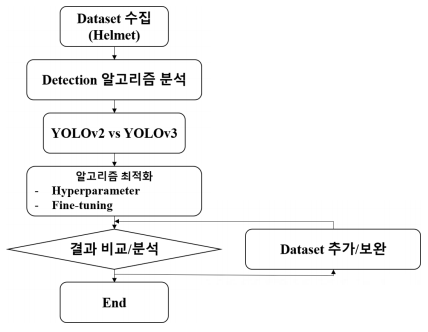
본 논문의 연구는 Fig. 2의 순서로 진행했으며, 1장은 서론 연구에 대한 전반적인 내용을 서술한다. 2장은 본론으로 알고리즘과 학습에 이용된 Dataset 그리고 모델 학습 결과를 비교하고, 3장은 결론 및 향후 연구 계획에 대하여 기술하였다.
2. 본 론
2.1 Object Detection 알고리즘 이전에도 안전모 탐지에 대해 지속적으로 연구되어 왔다. 객체 탐지를 위한 딥러닝 알고리즘 중 Faster-RCNN[2]을 기반으로 하여 안전모를 탐지하거나[3], R-FCN[4]을 기반으로 하여 거리, 밝기, 포즈 변화 등에 대한 안전모 탐지[5]를 실시한 선행 연구들이 있다. 선행되어진 연구들은 데이터 구축, 여러 상황에 따른 알고리즘 성능에 대해 분석 및 연구를 진행했다. 본 논문에서는 실시간으로 안전 보호구를 탐지하기 위해 객체 탐지에 대한 정확 보다는 영상처리 속도에 초점을 두었다. 다양한 알고리즘 중에서 영상 처리 속도에 중점을 둔 대표적인 알고리즘에 You Only Look Once(YOLO)[6] (Fig. 2)와 Single-Shot Detection (SSD)[7](Fig. 3) 두 가지가 존재한다. 두 알고리즘 에 대한 간단한 설명은 2.1.1과 2.1.2에 기술한다.
2.1.1 You Only Look Once(YOLO) YOLO[6]는 빠른 영상 처리 속도를 구현함으로써 실시간에 가장 가까운 영상 처리 속를 보여주고 있는 알고리즘이다.
이미지가 입력되면 이미지를 S × S의 사각형으로 나누어 각 사각형 마다 미리 설정된 B개의 영역을 지정하고, 각 영역마다 클래스의 확률을 예측한다. 각각의 영역은 식 (1)로 Confidence Score를 계산하고, 검출하고자 하는 클래스에 대해 식 (2)와 같은 조건부 확률을 가진다. 최종적으로 학습된 모델은 클래스 분류 시, 지정한 임계치(Threshold) 보다 높은 영역들 중 가장 높은 확률을 가진 영역을 최종적으로 클래스로 분류하게 된다.

그리고 특징추출기로 사용된 Darknet-53[6](Fig.3)은 YOLOv2버전에서 사용된 Darknet-19[8]를 확장한 모델로 총 53개 층으로 이루어져 있으며, 기존의 Darknet-19에서 Residual Block을 추가했다.

2.1.2 Single-Shot Multibox Detector(SSD) SSD는 YOLO 알고리즘과 함께 탐지 속도가 뛰어난 알고리즘으로, 특징 추출는 VGG-16[7]을 사용한다. YOLO 알고리즘과 가장 큰 차이점은 여러 개의 Feature map을 각각의 Feature map에 Convolutional layer를 사용하여 Output size를 줄여 여러 스케일의 객체를 탐지하고자 했습니다(Fig. 4).

본 논문에서는 두 알고리즘 중 Real-time에 가장 근접한 속도를 보여주는 YOLO 알고리즘[6]을 이용한다.
2.2 Dataset 수집
Dataset은 안전모탐지를 위해 선행 연구된 사진들을 3,884개의 이미지를 수집했다. Fig. 5의 유형과 같은 이미지들을 수집했다. 그리고 이미지들을 Training과 Validation을 위해 각각 70%:30%로 나누어 Training을 진행하였다.
Class는 ‘Person with Helmet, Person without Helmet’ 2가지로 나누어 학습을 진행하였고, 학습을 진행하기 이전 YOLO에서 Labelling을 위해 제공하는 Yolo-Mark[9]라는프로그램을사용하였다.

2.3 Mean Average Precision (mAP) mAP는 객체 탐지 알고리즘에서 가장 널리 사용되는 모델 성능 척도이다.
AP는 Precision과 Recall 그래프에서 그려진 면적을 계산한 값이다. Precision은 다음 식 (3)으로 표현할 수 있는데,

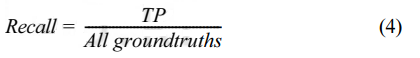
여기서 TP는 검출 결과가 옳게 된 것을 의미한다. 즉 Precision은 검출된 결과 중 옳게 검출된 것 을 의미한다.
그리고 Recall은다음의식 (4)으로표현할수있다.
Recall은 검출이 되어야할 모든 객체들에 대해 옳게 검출한 것을 의미한다. 위 식들을 이용하여 Precision-Recall 그래프가 그려지고, 구해진 AP값들의 평균값을 구한 값이 mAP이다. mAP 이외에도 다양한 모델 성능의 척도가 있지만, YOLO에서 제시한 성능과 비교를 위해 mAP를 이용하여 성능을 분석하였다.
3. 사례연구
3.1 YOLO 알고리즘 비교/분석
본 연구에 적합한 모델을 선정하기 위하여 YOLOv2와 YOLOv3 버전의 결과를 비교한다. 두 알고리즘의 성능 판단 기준 앞서 서술한 Mean Average Precision(mAP)을 사용한다.
본 연구에 더 적합한 알고리즘을 선택하기 위해 YOLO에서제시한두알고리즘의성능차이(mAP) 를 검증하기위해 두 알고리즘의 결과를 비교/분석하였다. 두알고리즘에대해동일한 Hyperparameter 를 적용하여 Training을 진행하였다.
Table 1은
YOLOv2와 YOLOv3의 Training 결과를 보여주고있다.
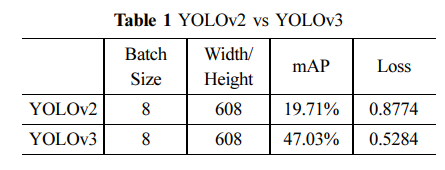
YOLOv2와 YOLOv3의 결과는 각각 19.71%와 47.03%로 결과 차이가 매우 큰 것을 볼 수 있다.
3.2 YOLOv3 알고리즘 최적화
Table 1에서비교한 YOLOv3의성능은 YOLOv2 보다는 높은 결과를 보여주고 있지만, 좋은 결과를 보여주지 않았다. 이후 Hyperparameter 조정과 Fine-tuning, Dataset을 변경을 통해 성능을 향상시 키고자 하였다.
3.2.1 Hyperparameter 수정
수정을 실시한 Hyperparameter는 Table 2를 보면 알 수 있다. Training을 1번 진행할 때 사용되는 이미지 수를 나타내는 Batch Size를 8, 64로 두었다. 이는 컴퓨터의 성능에 따라 차이를 둘 수 있다. 컴퓨터의 성능이 우수할수록 큰 숫자 BatchSize를 설정하여 매 학습마다 많은 수의 데이터를 처리할 수 있다.그리고 Training시에 입력되는 이미지의 크기를 조정하는 Image Size는 ‘416×416’과 ‘608×608’으로 나누었는데, YOLO에서 제시한 성능표에서 두 가지 Image Size에 대해서 성능차이를 보이고 있기에 두가지 조건으로 설정하였고 학습 시에 Padding(입력 데이터의 주변을 특정 값으로 채워 늘리는 것)을 진행해야 하기에 학습과정이 번거로 워지는 단점이 존재하여 이미지의 가로와 세로 값 을 동일하게 설정하였다. 최종적으로 4가지의 경 우를 두고 Training을 진행하였다.
Hyperparameter의 경우 마다 Training 결과는 Table에서 볼 수 있다. 먼저 Batch Size를 ‘8’로 두었을 때 Image Size를 달리 두었다. 그리고 각각의 경우에 대한 결과는 이미지 사이즈가 ‘608×608’일 때 mAP가 더 높게 나타났다. 다음으 Batch Size를 ‘64’로 두었을 때 이미지 사이즈 별 Training을 진행하였고, 여기서도 마찬가지로 이미지사이즈가 ‘608×608’ 일 때 더 좋은 성능을 나타내고 있다. Table 3의 결과들을 토대로 Batch Size와 Image Size가 클수록 더 좋은 결과를 나타내 있다. 하지만 가장 좋은 성능을 나타낸 경우에도 mAP가 약 57%로 낮은 성능을 나타내고 있다.

3.2.2 Fine-tuning 적용
mAP를 향상 더 향상시키기 위해 Fine-tuning 기
법을 적용하고자 한다. Fine-tuning은 Transfer
learning에 사용될 Dataset의 크기와 Pre-trained된