
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 영어공부
- 파이썬
- Ai
- machinevision
- 초보영어
- ComputerVision
- coding
- 파이썬gui
- C언어
- 직장인
- 머신비전
- 석사
- 동사
- Vision
- 영어회화
- 3dprinter
- 인공지능
- 오픽
- 프로그래밍
- Python
- 대학원
- 4차산업
- opencv
- 머신러닝
- 코딩
- 딥러닝
- 산업대학원
- 영어
- 특수대학원
- 영어기초
- Today
- Total
미래기술연구소
[패스트캠퍼스 수강 후기] 컴퓨터비전인강 100% 환급 챌린지 20 회차 본문
30일 남았다...
시간 진짜 빨리감
강제로 보게 되서 좋긴 좋네 허허..

오늘은 cnn
컨볼루션 신경망: CNN
▪ 컨볼루션 신경망(CNN: Convolutional Neural Network)
• 영상 인식 등을 위한 딥러닝에 특화된 네트워크 구조
• 일반적 구성: 컨볼루션(convolution) + 풀링(pooling) + … + 완전 연결 레이어(FC)

▪ 컨볼루션 레이어(Convolution Layer)
• 2차원 영상에서 유효한 특징(feature)를 찾아내는 역할
• 유용한 필터 마스크가 학습에 의해 결정됨
• 보통 ReLU 활성화 함수를 함께 사용함

▪ 풀링 레이어(Pooling Layer)
• 유용한 정보는 유지하면서 입력 크기를 줄임으로써 과적합(overfitting)을 예방하고 계산량을 감소시키는 효과
• 최대 풀링(max pooling) 또는 평균 풀링(average pooling) 사용
• 학습이 필요 없음

▪ 완전 연결 레이어(Fully Connected Layer)
• 3차원 구조의 activation map(H W C)의 모든 값을 일렬로 이어 붙임 • 인식의 경우, 소프트맥스(softmax) 레이어를 추가하여 각 클래스에 대한 확률 값을 결과로 얻음
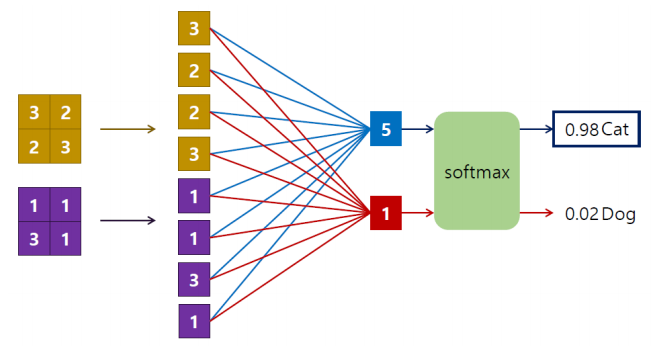
▪ 학습된 컨볼루션 레이어 필터의 예

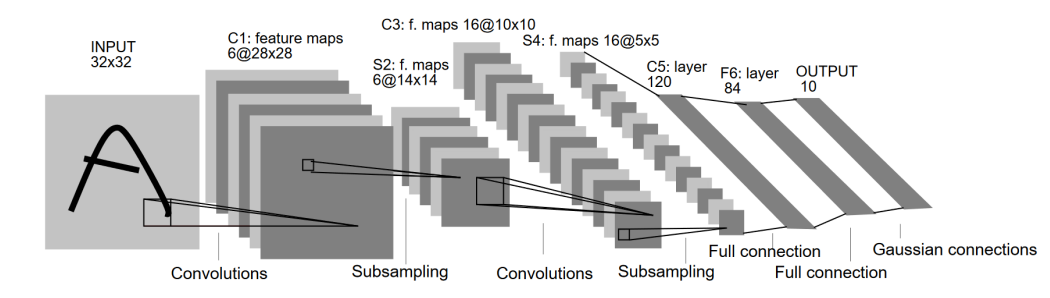
▪ 필기체 숫자 인식을 위한 LeNet-5 (LeCun et al., 1998)
• CNN 원조 • 28x28 필기체 숫자 영상을 32x32로 확장하여 만든 입력 데이터를 사용
• 전체 7개 레이어: Conv-Pool-Conv-Pool-FC-FC-FC
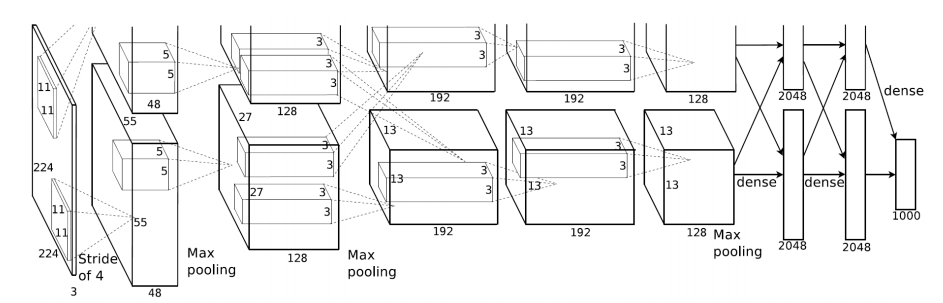
▪ AlexNet (Krizhevsky et al., 2012)
• 2012년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 영상 인식 분야 1위
▪ 1000개의 카테고리, 120만개의 훈련 영상, 15만개의 테스트 영상
• Top-5 Error: 15.4% (다른 컴퓨터 비전 기반 방법들 > 25%)
• 하드웨어의 제약으로 2개의 GPU 사용
▪ VGG16 (Simonyan and Zisserman, 2014)
• 2014년 ILSVRC(ImageNet Large Scale Visual Recognition Competition) 영상 인식 분야 2위
• Top-5 Error: 7.3%
• 컨볼루션 레이어에서 3x3 필터만 사용
• 총 16개 레이어로 구성

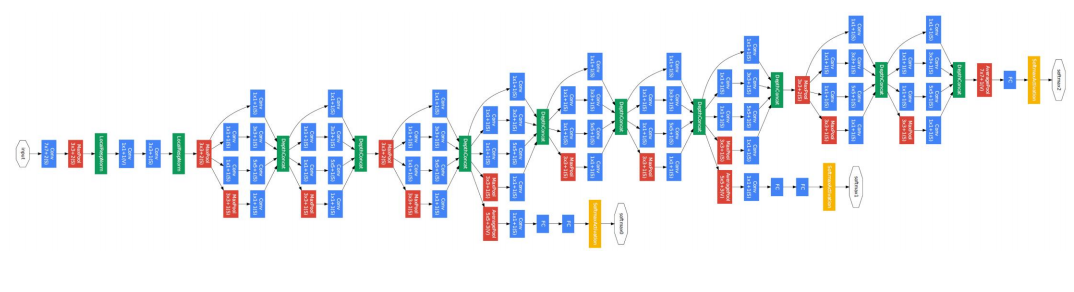
▪ GoogLeNet (Szegedy et al., 2014)
• 2014년 ILSVRC(ImageNet Large Scale Visual Recognition Competition) 영상 인식 분야 1위
• Top-5 Error: 6.7% (사람: 5.1%)
• 총 22개의 레이어로 구성
• Inception 모듈

'etc > FastCampus 챌린지' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 컴퓨터비전인강 100% 환급 챌린지 22 회차 (0) | 2020.11.09 |
|---|---|
| [패스트캠퍼스 수강 후기] 컴퓨터비전인강 100% 환급 챌린지 21 회차 (0) | 2020.11.08 |
| [패스트캠퍼스 수강 후기] 컴퓨터비전인강 100% 환급 챌린지 19 회차 (0) | 2020.11.06 |
| [패스트캠퍼스 수강 후기] 컴퓨터비전인강 100% 환급 챌린지 18 회차 (0) | 2020.11.05 |
| [패스트캠퍼스 수강 후기] 컴퓨터비전인강 100% 환급 챌린지 17 회차 (0) | 2020.11.04 |



