
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Python
- coding
- 영어
- 인공지능
- 딥러닝
- 산업대학원
- 파이썬
- machinevision
- 석사
- 초보영어
- 영어기초
- 동사
- 직장인
- 프로그래밍
- 머신러닝
- Ai
- C언어
- 3dprinter
- ComputerVision
- 코딩
- 영어공부
- opencv
- 머신비전
- 영어회화
- 대학원
- 오픽
- Vision
- 특수대학원
- 4차산업
- 파이썬gui
- Today
- Total
미래기술연구소
Gaussian Mixture Model GMM 본문
Gaussian Mixture Model (GMM)은 이름 그대로 Gaussian 분포가 여러 개 혼합된 clustering 알고리즘이다. 현실에 존재하는 복잡한 형태의 확률 분포를 [그림 1]과 같이 KK개의 Gaussian distribution을 혼합하여 표현하자는 것이 GMM의 기본 아이디어이다. 이때 KK는 데이터를 분석하고자 하는 사람이 직접 설정해야 한다.

[그림 1] 여러 Gaussian distribution의 혼합 분포
주어진 데이터 xx에 대해 GMM은 xx가 발생할 확률을 [식 1]과 같이 여러 Gaussian probability density function의 합으로 표현한다.

[식 1]에서 mixing coefficient라고 하는 πkπk는 kk번째 Gaussian distribution이 선택될 확률을 나타낸다. 따라서, πkπk는 아래의 두 조건을 만족해야 한다.


GMM을 학습시킨다는 것은 주어진 데이터 X={x1,x2,...,xN}X={x1,x2,...,xN}에 대하여 적절한 πk,μk,Σkπk,μk,Σk를 추정하는 것과 같다.
2. GMM을 이용한 classification
GMM을 이용한 classification은 주어진 데이터 xnxn에 대해 이 데이터가 어떠한 Gaussian distribution에서 생성되었는지를 찾는 것이다. 이를 위해 responsibility γ(znk)γ(znk)를 [식 4]와 같이 정의한다.

[식 4]에서 znk∈{0,1}znk∈{0,1}는 xnxn이 주어졌을 때 GMM의 kk번째 Gaussian distribution이 선택되면 1, 아니면 0의 값을 갖는 binary variable이다. 즉, znkznk가 1이라는 것은 xnxn이 kk번째 Gaussian distribution에서 생성되었다는 것을 의미한다. GMM을 이용한 classification은 xnxn이 주어졌을 때, kk개의 γ(znk)γ(znk)를 계산하여 가장 값이 높은 Gaussian distribution을 선택하는 것이다.
학습을 통해 GMM의 모든 parameter π,μ,Σπ,μ,Σ의 값이 결정되었다면, 베이즈 정리(Bayes' theorem)을 이용하여 γ(znk)γ(znk)를 다음과 같이 계산할 수 있다.
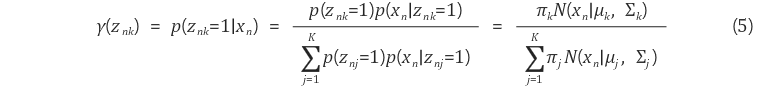
πkπk와 p(znk=1)p(znk=1)은 모두 kk번째 Gaussian distribution이 선택될 확률을 나타내기 때문에 [식 5]에서는 p(znj=1)p(znj=1)가 πjπj로 치환되었다.
3. Expectation-maximization algorithm (EM algorithm)을 이용한 GMM의 학습
일반적으로 GMM은 주어진 데이터 X={x1,x2,...,xN}X={x1,x2,...,xN}에 대해 EM 알고리즘을 적용하여 GMM을 구성하는 parameter인 π,μ,Σπ,μ,Σ를 추정한다. Parameter를 추정하기 위해 먼저 [식 6]과 같이 log-likelihood L(X;θ)L(X;θ)를 정의한다.

직관적으로 likelihood는 어떠한 모델에서 데이터 X={x1,x2,...,xN}X={x1,x2,...,xN}가 생성되었을 확률을 나타낸다. [식 6]에서 정의한 log-likelihood는 기본적인 likelihood와 동일한 의미를 가지며, 계산상의 편의를 위해 likelihood에 log를 취한 형태이다. 따라서, log-likelihood를 최대화하는 π,μ,Σπ,μ,Σ 추정하는 것은 주어진 데이터 XX를 가장 잘 표현하는 GMM을 구성하는 것과 동일한 의미를 갖는다.
이를 위해 각각의 πk,μk,Σkπk,μk,Σk에 대해 L(X;θ)L(X;θ)를 편미분한다. Log-likelihood를 최대화하기 위한 μkμk의 추정 과정은 아래와 같다.


Σk는 다음과 같이 계산된다.
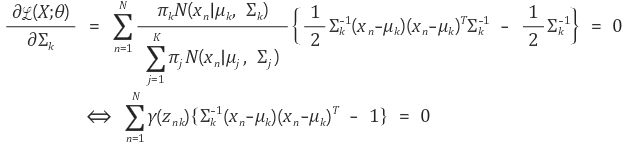

GMM의 마지막 parameter인 πkπk는 [식 3]의 조건을 만족하면서 log-likelihood를 최대화해야 한다. 따라서, πkπk는 라그랑주 승수법 (Lagrange multiplier method)을 이용하여 추정하며, 라그랑지안 J(X;θ,λ)J(X;θ,λ)는 [식 9]와 같다
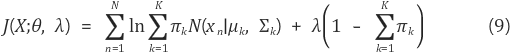
J(X;θ,λ)J(X;θ,λ)를 πkπk에 대해 편미분하면 다음과 같이 λλ를 계산할 수 있다.
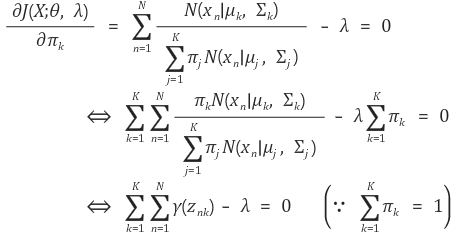

위의 과정을 통해 계산한 λλ를 이용하여 다음과 같이 πkπk를 추정할 수 있다.


GMM의 parameter 추정을 위한 EM 알고리즘의 E-step에서는 모든 데이터와 Gaussian distribution에 대해 γ(znk)γ(znk)를 계산한다. 그 다음, M-step에서는 [식 7, 8, 11]을 이용하여 모든 Gaussian distribution에 대한 π,μ,Σπ,μ,Σ를 추정한다. 이러한 E-step과 M-step을 일정 횟수 또는 수렴할 때까지 반복한다.
4. 구현
EM 알고리즘을 이용한 GMM의 parameter는 아래의 [알고리즘 1]과 같이 추정된다.

입력받은 데이터 X={x1,x2,...,xN}X={x1,x2,...,xN}에 대한 classification은 [알고리즘 2]와 같이 수행된다.

출처 : https://untitledtblog.tistory.com/133
'Industry 4.0 > Machine Learning' 카테고리의 다른 글
| Machine Learning Classification (0) | 2020.08.06 |
|---|---|
| Data Set & 독립변수 , 종속변수 (0) | 2020.08.06 |
| 머신 러닝의 순서 (0) | 2020.07.02 |
| 선형회귀를 통한 머신 러닝의 개념 이해 (0) | 2020.06.08 |
| Machine & Deep Learning (0) | 2020.06.07 |



